
Language documentation infrastructure, from recording to Archival.
GlossKit coordinates recordings, transcription review, morphology, lexicon curation, syntax, and archival export in a modular workflow designed for linguists, documentation teams, and community-centered research.
GlossKit brings the moving parts of language documentation into one coordinated platform: recordings, reviewed transcripts, morphological analyses, lexicon evidence, syntax initialization, and export-oriented project data. It is designed to make documentation work more traceable, reusable, and collaborative while keeping human linguistic judgment at the center.
- Built around projects, texts, consultants, and structured metadata.
- Supports human-in-the-loop review across analysis stages.
- Designed to connect documentation work with export and archival packaging.
Illustrative product workflow, not live project data.
Audio Segmentation
Concept illustration
Transcript
paşayek ʔebê le memleketêkî
Interlinear Gloss
paşa
king
NOUN
-yek
indf
ʔebê
be.prs
VERB
Dependency Parse
nsubj
padşa
root
bê
Export Package
CoNLL-U, ELAN, JSON
Language documentation workflows are powerful, but fragmented.
Many documentation projects rely on a patchwork of tools, file conventions, spreadsheets, annotations, and local workarounds. That flexibility is valuable, but it can make it difficult to keep recordings, transcripts, morphological decisions, lexicon evidence, syntax, and export materials aligned over time.
Recording and segmentation
Recordings often begin in one tool, segment definitions in another, and project metadata somewhere else entirely. As a result, audio handling, consultant context, and segmentation decisions can drift apart.
GlossKit is designed to connect recording metadata, segmentation-oriented workflows, and downstream text analysis more directly.
Transcription
Transcription is rarely a single-pass task. Researchers often need machine assistance, manual revision, and a clear record of what has been reviewed.
GlossKit currently supports queued transcription workflows with transcript editing and is being developed toward tighter review and feedback loops.
Morphological analysis
Morphological work depends on repeated token-level decisions, revisions, and consistency across a project. Without structure, approvals and downstream reuse become difficult to manage.
GlossKit currently supports approval-based morphology workflows with a distinction between editable input and finalized glosses.
Lexicon building
Useful lexicons are not just word lists. They require evidence, examples, and deliberate curation from analyzed texts.
GlossKit currently supports evidence-based lexicon building from finalized morphology rather than silent auto-generation.
Syntax and treebanks
Syntax work often begins with imperfect first guesses that still need to preserve links back to the underlying analysis. If those links are weak, treebank work becomes harder to trust and revise.
GlossKit is designed to generate editable first-pass UD-style parses from morphology while preserving a review workflow for correction and approval.
Export and archiving
Export is often treated as an afterthought, even though documentation projects eventually need structured outputs for sharing, deposit, or later publication work.
GlossKit currently supports multi-module export packaging and is being developed toward broader archival and publication-oriented coverage.
A coordinated workflow, stage by stage
Upload recordings or create texts, review transcription outputs, approve morphology analyses, generate first-pass syntax parses, and assemble export packages in a workflow designed to stay connected across stages.
Upload
Recording intake
Upload recordings or create text records inside a project-oriented workflow. Recording metadata and text state are meant to stay connected from the beginning.
Segment
Segmentation workflow
Prepare recordings for transcript work and segment-oriented analysis. The backend includes segmentation machinery, but the polished end-to-end workflow still needs deeper validation.
Transcribe
Queued ASR review
Queue transcription jobs, retrieve transcript outputs, and revise transcript text through a human review step. The system is designed around review rather than unattended automation.
Gloss
Morphology workspace
Move from segmented text into token-level analysis, approval workflows, review cards, and finalized glosses for downstream use. The backend audit identifies Morphology as one of the more developed analysis modules.
Curate Lexicon
Evidence-first curation
Import finalized glosses as evidence, group candidate items, and curate dictionary entries with linked examples. This keeps lexicon building tied to reviewed analytical evidence.
Parse Syntax
UD-style initialization
Generate editable first-pass dependency parses from finalized morphology and review them sentence by sentence. The workflow is real, but parse quality and export ergonomics remain under active development.
Export
Structured outputs
Assemble analysis outputs and project metadata into export-oriented files and bundles. Export exists today, but coverage varies by module and data state.
Archive / Publish
Packaging for deposit
Prepare project materials for archival handoff and future publication-oriented work. The platform provides a foundation for this, but comprehensive publication workflows are still planned and expanding.
Purpose-built modules for the documentation pipeline
The platform is organized as a modular workflow rather than a single monolithic tool. Each module addresses a specific stage while preserving links to project context and downstream outputs.
Gateway / Project Workspace
GlossKit includes a central project workspace layer that coordinates users, projects, collaborators, consultants, texts, and cross-module state. It acts as the organizing layer that connects recordings and texts to downstream analysis services.
Current backend foundation
Project and collaborator management, text and segment state, consultant and location metadata, and cross-module orchestration.
Still being developed
Stronger deployment hardening, tighter integration validation, and more robust service-boundary enforcement.
Technical credibility
The current backend already persists project, text, collaborator, consultant, and cross-module completion state through a dedicated gateway service.
ASR & Segmentation
GlossKit includes an ASR layer for recording upload, media normalization, queued transcription jobs, transcript retrieval, and transcript editing. It already functions as a real ingestion and transcription component, but some training-related and legacy API paths remain partial or placeholder implementations.
Current backend foundation
Recording upload, audio normalization, queued transcription, transcript editing, and EAF-related export handling.
Still being developed
Stronger segmentation validation, tighter correction-to-model feedback loops, and clearer retirement of older placeholder route surfaces.
Technical credibility
The service already uses a queue-backed worker model for transcription rather than presenting transcription as a simple front-end mockup.
Morphology
GlossKit’s morphology workspace supports token-level analysis, approvals, review cards, project lexicon learning, and final gloss locking for downstream workflows. The backend audit identifies Morphology as one of the more developed analysis modules.
Current backend foundation
Project-scoped morphology documents, approval-based glossing, lexicon learning from approvals, finalized gloss export, and shared base-library selection.
Still being developed
Stronger standalone service isolation, clearer consolidation of legacy and newer base-library concepts, and richer downstream syntax payloads.
Technical credibility
The morphology layer already persists approved analyses, morpheme occurrences, and versioned grammar and lexicon state in a structured backend model.
Lexicon
GlossKit supports evidence-based lexicon curation from finalized morphological analysis rather than silently auto-generating dictionary entries. It is currently implemented within the morphology backend as a deliberate downstream curation workflow.
Current backend foundation
Import from locked glosses, evidence grouping, candidate review, curated entry creation, and provenance-bearing examples.
Still being developed
Cleaner separation from older legacy lexicon paths, richer export workflows, and stronger source-metadata handling on evidence items.
Technical credibility
The current design explicitly distinguishes evidence tables from curated dictionary entries, which is a stronger foundation than simple auto-populated word lists.
Syntax & UD Treebanking
GlossKit can generate editable first-pass dependency parses from finalized morphology in a UD-style structure and preserve user edits and approvals. The backend includes a working foundation for this review workflow, but the automatic first guess remains heuristic rather than high-confidence.
Current backend foundation
Morphology-to-syntax parsing, sentence persistence, token-level editing, save and approve flows, and CoNLL-U-like serialization.
Still being developed
Stronger parse heuristics, fuller preservation of morphology detail, and more complete user-facing export and review ergonomics.
Technical credibility
The syntax module already persists documents, sentences, token annotations, and safe reparsing behavior rather than functioning as a disposable preview layer.
Archival Export
GlossKit includes an archival export layer that can assemble project metadata and selected outputs from multiple modules into a structured bundle. The archival layer provides an early export-oriented foundation, though it remains less broadly tested than some core analysis modules.
Current backend foundation
Multi-service archive bundling, inclusion of syntax outputs, EAF and audio-related artifacts, curated lexicon content, and optional text-oriented files.
Still being developed
Larger-scale export handling, broader test coverage, and clearer behavior when some downstream modules are incomplete.
Technical credibility
The archival service already resolves project data across multiple backend modules and assembles structured export bundles rather than exporting isolated files only.
Phonology
Phonology is part of the broader product direction for GlossKit, especially where documentation workflows need closer integration with segmental analysis, alignment, and sound-focused annotation. It is not yet a verified standalone backend module in the current audit.
Current backend foundation
Product direction only.
Still being developed
Module definition, workflow scope, and implementation path.
Technical credibility
The current backend audit does not verify a separate phonology service, so this is presented as planned work rather than active functionality.
Grammar Writing
GlossKit is intended to support later-stage grammar-writing and publication-oriented workflows by carrying structured analyses forward into exportable materials. The current audit shows some text and LaTeX-oriented export capability, but not a dedicated grammar-writing module.
Current backend foundation
Early foundations through export-oriented structured data and optional text-based outputs.
Still being developed
Dedicated grammar-writing workflows, templates, and module-specific authoring support.
Technical credibility
The platform already preserves structured intermediate analysis that could support later grammar-writing workflows, but the dedicated module remains roadmap work.
Collaboration, governance, and transparent review
GlossKit is organized around projects rather than isolated files. That structure makes it possible to keep consultant information, location context, text state, and downstream analysis steps connected as work moves across transcription, morphology, lexicon curation, syntax, and export.
Automation in GlossKit is intended to be transparent and reviewable. Transcription suggestions, morphology approvals, lexicon curation, and syntax initialization are most useful when they remain visible to the people responsible for the analysis.
Project-based collaboration
Support collaboration without hiding who reviewed what or where a text stands in the workflow.
Consultant and location metadata
Keep consultant context, project metadata, and downstream analysis stages connected rather than scattered across separate files.
Human review
Keep review central across transcription, morphology, lexicon curation, syntax, and export decisions.
Controlled access
Treat controlled access as a project-level design concern without overstating current hardening or audit scope.
Community-centered documentation
Make consultation, permissions, metadata context, and human review easier to maintain rather than easier to bypass.
Transparent automation
Keep machine-assisted steps inspectable and revisable instead of treating them as final outputs.
Outputs for review, reuse, and archival handoff
GlossKit is intended to help teams prepare structured outputs for archives, researchers, and publication-oriented workflows while keeping claim boundaries cautious.
Time-aligned transcripts
Partially supportedGlossKit supports transcript retrieval, transcript editing, and segment-aware recording workflows, with export-oriented alignment through ASR-related artifacts.
Interlinear glossed texts
SupportedFinalized morphology can produce reviewed glossed analysis suitable for downstream parsing and later export workflows.
Morphological lexicon
SupportedProject lexicon learning from approved morphology is already part of the current workflow.
Evidence-based dictionary entries
SupportedCurated lexicon entries can be created deliberately from reviewed evidence with linked examples and provenance.
CoNLL-U / UD-style syntax data
Partially supportedSyntax includes UD-style parsing and CoNLL-U-like serialization, but automatic quality and user-facing export ergonomics remain under active development.
EAF-related exports
SupportedGlossKit can generate EAF-related export materials through its ASR and archival workflows.
JSON / XML / LaTeX-oriented exports
Partially supportedThe current export layer can emit some structured text-oriented outputs, while broader publication-oriented coverage remains under active development.
Archive packages
Partially supportedMulti-module archive bundling is real, but current robustness depends on downstream module completeness and remains lightly tested.
Illustrative ELAN-style export
A conceptual example of the kind of time-aligned, multi-tier record GlossKit is intended to help teams prepare.
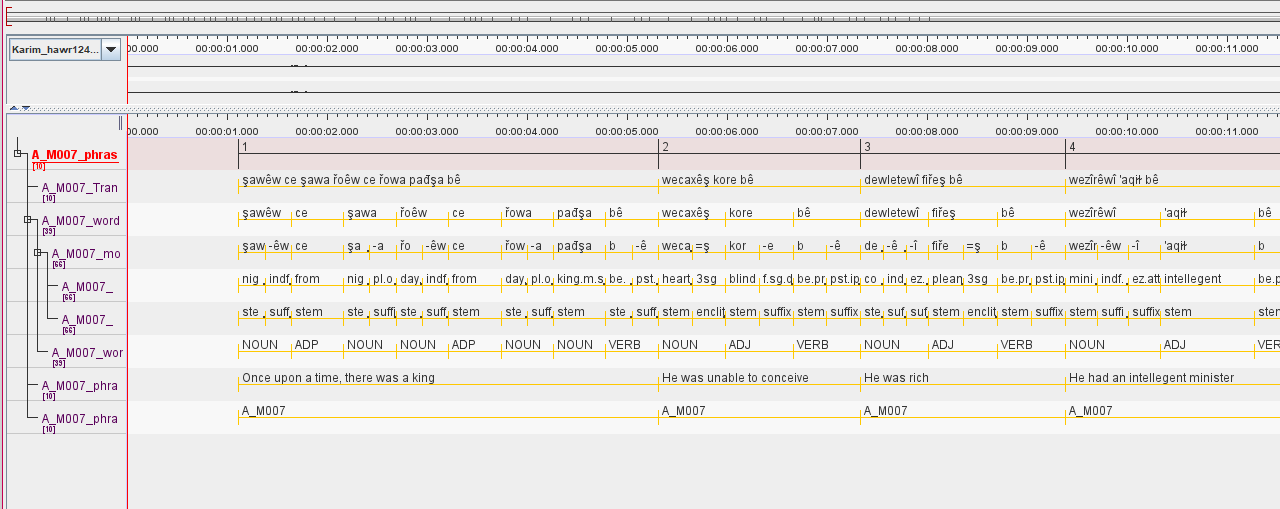
Example structure
Phrase · word · gloss · translation
Planned targets
ELAN · FLEx · CoNLL-U
Workflow intent
Reviewable and structured
Archive context
Subject to archive requirements
Tutorial topics in preparation
Video tutorials will be added as they are recorded and linked from YouTube. The initial tutorial library is intended to mirror the real workflow of the platform rather than generic software onboarding.
Getting Started
Orientation to projects, texts, consultants, and workflow structure.
ASR & Segmentation
Recording ingestion, transcript review, and segmentation-aware processing.
Morphology
Token analysis, approvals, review cards, and finalized gloss workflows.
Lexicon
Importing evidence from finalized glosses and curating dictionary entries.
Syntax & UD
Working with first-pass parses, sentence review, and correction workflows.
Export & Archiving
Preparing project outputs, archive packages, and downstream handoff.

Built by a linguist for linguists.
GlossKit is being developed by Shuan Osman Karim, a historical linguist and language documentation researcher working on Kurdish, Gorani, and other underdocumented Iranic languages. The platform reflects practical experience with the bottlenecks that connect recordings, transcription, morphological analysis, lexicon curation, syntax, and export.
Read the founder storyBring documentation workflows into one coordinated platform.
GlossKit is being developed for teams who need serious infrastructure for reviewed language documentation work. If you are planning a project, evaluating tooling, or coordinating future collaboration, we would be glad to hear from you.